Mar 28, 2026
Overview
pg_duckpipe is a PostgreSQL extension that brings real-time Change Data Capture (CDC) to your database. It continuously syncs your regular heap tables into DuckLake columnar tables via PostgreSQL’s WAL, enabling you to run transactional and analytical workloads in a single database. No Kafka, no Debezium, no external orchestrator. Just PostgreSQL.
We have been shipping fast. Here is what landed recently:
- Transparent query routing: analytical SELECTs are automatically redirected to columnar DuckLake tables
- Append sync mode: immutable changelog with exactly-once semantics, SCD Type 2, and no-PK table support
- Fan-in streaming: consolidate multiple source databases into a single analytical table
- Partitioned table support: sync partitioned tables with zero extra configuration
- Hierarchical configuration: tune flush behavior at global, group, or per-table granularity
- Schema DDL propagation: ADD, DROP, and RENAME COLUMN automatically sync to DuckLake targets
- Stability and observability: spillable flush buffers, concurrent flush control, and metrics
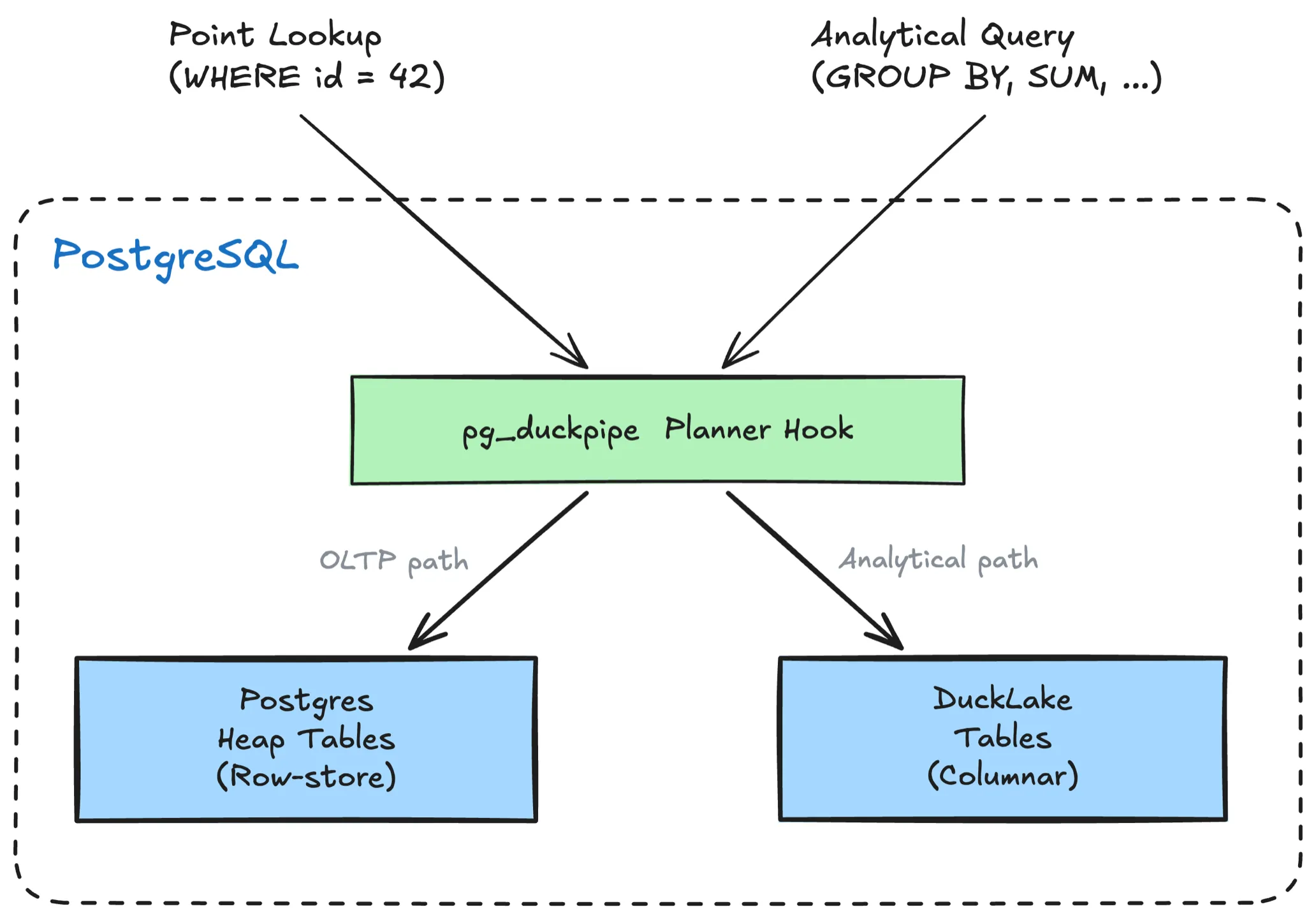
Transparent Query Routing
pg_duckpipe now includes a planner hook that transparently rewrites SELECT queries on synced source tables to their DuckLake columnar counterparts. No query changes needed.
SET duckpipe.query_routing = 'auto';
-- This query hits the columnar DuckLake copy automatically
SELECT customer_id, sum(total), count(*)
FROM orders
GROUP BY customer_id;Three routing modes are available:
| Mode | Behavior |
|---|---|
off | No routing (default) |
on | Route all SELECTs to DuckLake |
auto | Route analytical queries; skip PK lookups |
The auto mode is the sweet spot for HTAP: point lookups stay on the heap for low-latency OLTP, while analytical scans shift to columnar storage. Per-table control is available via table-level config.
Append Sync Mode
The default upsert mode maintains a live copy of the source table. The new append mode takes a different approach: every change becomes a new row in an immutable changelog, essentially SCD Type 2 built into the CDC pipeline.
SELECT duckpipe.add_table('public.events', sync_mode => 'append');Each row gets _duckpipe_op (I/U/D) and _duckpipe_lsn metadata columns. For example:
INSERT INTO customers(id, name, email)
VALUES (1, 'Alice', 'alice@old.com');
UPDATE customers SET email = 'alice@new.com' WHERE id = 1;
DELETE FROM customers WHERE id = 1;The append-mode DuckLake target captures every version:
id | name | email | _duckpipe_op | _duckpipe_lsn
----+-------+----------------+--------------+---------------
1 | Alice | alice@old.com | I | 10485800
1 | Alice | alice@new.com | U | 10486920
1 | Alice | alice@new.com | D | 10487104Correctness is guaranteed by exactly-once semantics via dual-layer deduplication. No duplicates, no gaps, even after crashes or restarts.
Append mode also unlocks syncing for tables without a primary key, since the changelog does not need to identify rows for upsert:
SELECT duckpipe.add_table('public.raw_events', sync_mode => 'append');This makes append mode a natural fit for audit trails, event sourcing, and logging system analytics.
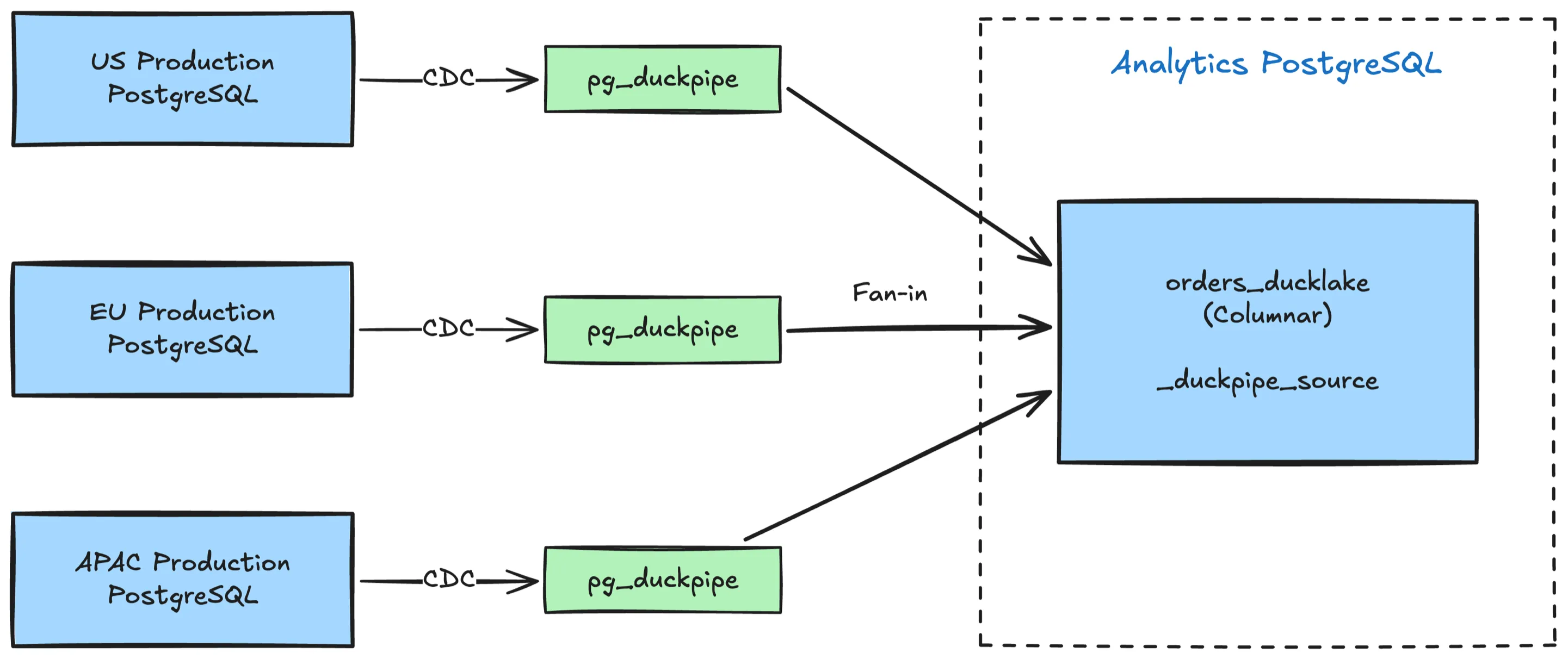
Fan-In Streaming
Fan-in lets you stream multiple source databases into a single DuckLake target table. Every row gets a _duckpipe_source column populated with the sync group name, so you can always trace which source a row came from.
-- Sync orders from two production databases into one analytical table
SELECT duckpipe.create_group('us_prod',
conninfo => 'host=us-prod.example.com ...');
SELECT duckpipe.create_group('eu_prod',
conninfo => 'host=eu-prod.example.com ...');
SELECT duckpipe.add_table('public.orders', sync_group => 'us_prod');
SELECT duckpipe.add_table('public.orders', sync_group => 'eu_prod', fan_in => true);
-- Query across both sources
SELECT _duckpipe_source, count(*), sum(total)
FROM orders_ducklake
GROUP BY _duckpipe_source;The _duckpipe_source column enables Parquet file-level pruning when filtering by source, and all mutation operations (DELETE, TRUNCATE, resync) are source-scoped. Sources never interfere with each other, so performance stays constant as you add more.
Partitioned Table Support
pg_duckpipe now auto-detects partitioned source tables. Just add the parent table and data from all child partitions will appear in the target DuckLake table as a unified view.
Hierarchical Configuration
Configuration is now a 4-tier hierarchy: hardcoded defaults, global config, per-group overrides, and per-table overrides. The most specific setting wins.
-- Set a global default
SELECT duckpipe.set_config('flush_interval_ms', '10000');
-- Override for a specific group
SELECT duckpipe.set_group_config('high_throughput', 'flush_interval_ms', '2000');
-- Override for a specific table
SELECT duckpipe.set_table_config('public.orders', 'flush_batch_threshold', '50000');This lets you tune hot tables differently from cold ones without changing global settings.
Schema DDL Propagation
Schema changes on the source table are now automatically propagated to the DuckLake target. Supported operations:
ADD COLUMN: new column appears in the target tableDROP COLUMN: column is removed from the target tableRENAME COLUMN: column name is updated in the target table
DDL detection works by diffing the RELATION messages in the WAL stream, so no event triggers or external hooks are needed. The flush thread drains old-schema data before applying the schema change, ensuring every batch is processed with the correct column layout.
ALTER COLUMN TYPE is currently blocked to prevent silent data corruption in existing Parquet files. Widening type changes (e.g. INT to BIGINT, VARCHAR(50) to VARCHAR(200)) will be supported in the near future.
Stability and Observability
Several improvements make pg_duckpipe more stable and observable under production workloads:
- Spillable flush buffer: flush threads now use a DuckDB buffer table that spills to disk when memory pressure is high, preventing OOM crashes on large batches.
- Concurrent flush control: a
FlushGatesemaphore limits concurrent flushes per sync group (default: 4). Threads that can’t acquire a slot continue buffering and retry on the next cycle. - Shared memory metrics: the new
duckpipe.metrics()function returns a JSON snapshot of pipeline health:
SELECT duckpipe.metrics();
-- output
{
"tables": {
"table_1": {
"queued_changes": 128,
"total_queued_changes": 584320,
"flush_count": 1247,
"flush_duration_ms": 34500,
"avg_row_bytes": 142,
"is_backpressured": false
}
},
"groups": {
"group_1": {
"total_queued_changes": 584320,
"is_backpressured": false
}
}
}At a glance you can see queue depth, flush throughput, per-row storage cost, and whether backpressure is active.
Other Improvements
- Access control:
add_table()now auto-grantsSELECTon the DuckLake target table to the source table owner, so existing access patterns carry over without manual GRANT statements. - Fix JSONB/JSON support:
jsonbandjsoncolumns are mapped to DuckDB’s nativeJSONtype.
What’s Next
We are continuing to push on:
- JSONB to VARIANT mapping: map PostgreSQL
jsonbcolumns to DuckDB’s nativeVARIANTtype for richer semi-structured analytics on the columnar side - Compaction and retention policies: automatic Parquet file merging and time-based data expiry
- Broader PostgreSQL version support: PG 16 and earlier
Try it out at GitHub: github.com/relytcloud/pg_duckpipe