@qianzhen
Mar 10, 2026
TL;DR: pg_duckpipe is a new PostgreSQL extension that continuously syncs your regular heap tables into DuckLake columnar tables via WAL-based CDC. One SQL call to start, no external infrastructure required.
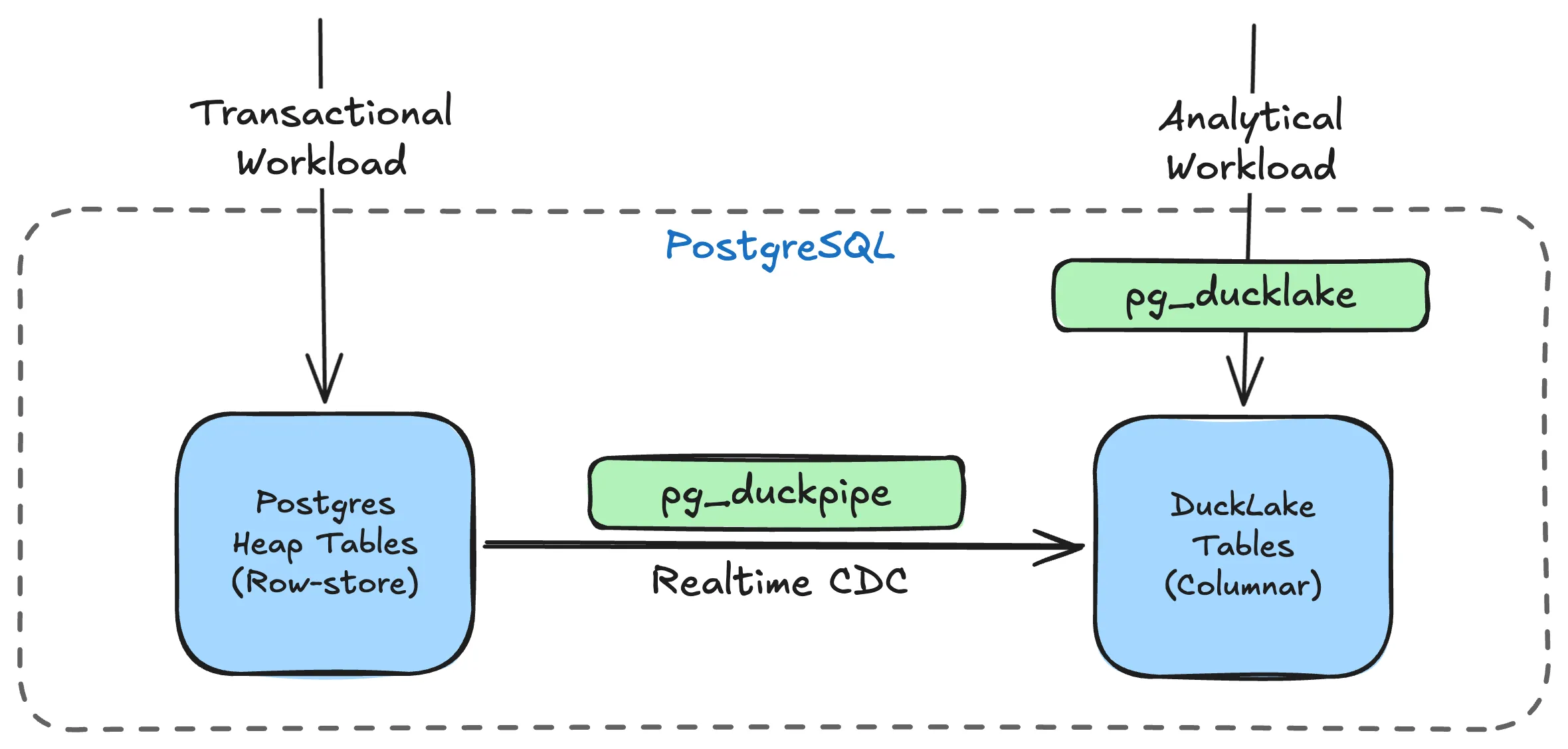
Why pg_duckpipe?
When we released pg_ducklake, it brought a columnar lakehouse storage layer to PostgreSQL: DuckDB-powered analytical tables backed by Parquet, with metadata living in PostgreSQL’s own catalog. One question kept coming up: how do I keep these analytical tables in sync with my transactional tables automatically?
This is a real problem. If you manage DuckLake tables by hand, running periodic ETL jobs or batch inserts, you end up with stale data, extra scripts to maintain, and an operational surface area that grows with every table. For teams that want fresh analytical views of their OLTP data, this quickly becomes painful.
pg_duckpipe addresses this. It is a PostgreSQL extension (and optionally a standalone daemon) that streams changes from regular heap tables into DuckLake columnar tables in real time. No Kafka, no Debezium, no external orchestrator. Just PostgreSQL.
Getting Started
Docker ships both pg_ducklake and pg_duckpipe pre-configured:
docker run -d --name duckpipe \
-p 15432:5432 \
-e POSTGRES_PASSWORD=duckdb \
pgducklake/pgduckpipe:18-mainSync a Local Table
Sync a heap table into a columnar copy for analytical queries:
-- Connect to the database
psql -h localhost -p 15432 -U postgres
-- Create a table and insert some data
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
customer_id BIGINT,
total INT,
created_at TIMESTAMP DEFAULT now()
);
INSERT INTO orders(customer_id, total)
SELECT (random() * 1000)::bigint, (random() * 10000)::int
FROM generate_series(1, 100000);
-- Start syncing to a columnar copy
SELECT duckpipe.add_table('public.orders');
-- Query the columnar copy
SELECT customer_id, sum(total), count(*)
FROM orders_ducklake
GROUP BY customer_id
ORDER BY sum(total) DESC
LIMIT 10;Sync from a Remote PostgreSQL
pg_duckpipe can replicate from a remote PostgreSQL instance. The source database does not need pg_duckpipe or pg_ducklake installed. It only needs wal_level = logical and a replication user. This makes it easy to add an analytical layer to an existing production database:
-- Create a sync group pointing to the remote database
SELECT duckpipe.create_group('prod_replica',
conninfo => 'host=prod-db.example.com port=5432 dbname=myapp user=replicator');
-- Add tables to sync
SELECT duckpipe.add_table('public.orders', sync_group => 'prod_replica');
SELECT duckpipe.add_table('public.customers', sync_group => 'prod_replica');
-- Check sync progress
SELECT source_table, state, rows_synced FROM duckpipe.status();Under the Hood
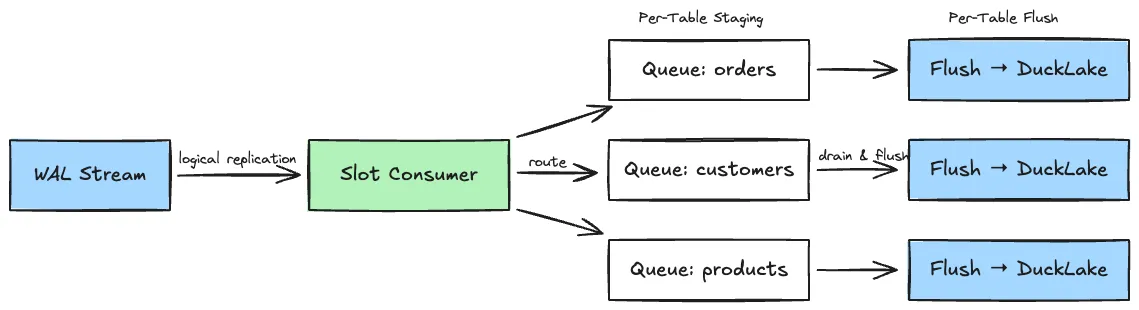
pg_duckpipe is written in Rust. Here is how changes flow from source to lakehouse:
- Tail the WAL stream. Connect to PostgreSQL’s logical replication protocol via the
pgoutputplugin. - Decode and route. Parse each change and dispatch it to a per-table in-memory queue.
- Flush to DuckLake. Batch-write queued changes into DuckLake columnar tables through embedded DuckDB connections.
A few design choices worth noting:
- Per-table isolation. Each synced table progresses through its own state machine (SNAPSHOT, CATCHUP, STREAMING) independently. A failure in one table never blocks another.
- Backpressure. If flush workers fall behind, the slot consumer pauses WAL consumption rather than accumulating unbounded memory.
- Crash safety. Per-table LSN tracking and an idempotent DELETE+INSERT flush path ensure at-least-once delivery with correct replay after restarts.
For a deeper look at the architecture, checkout the codebase and docs.
Roadmap
pg_duckpipe is under active development. Here is what we are working on next:
-
Functionality: schema DDL propagation, broader PostgreSQL version support.
-
Performance: flush worker thread pool, bounded queues, adaptive batching.
-
Maintenance & Observability: auto-compaction, scheduled flush policies, per-table lag metrics.
Give it a try, open an issue if something breaks, and send a PR if you want to help shape it. Let’s start duck piping!