@qianzhen
Jan 22, 2026
PostgreSQL is The World’s Most Advanced Open Source Relational Database[1]. It has the broadest and most mature ecosystem in the modern data stack: from AI integrations, JDBC drivers, and ORMs, to robust tooling for monitoring, backups and replication. But PostgreSQL is fundamentally a row-store designed for transactions, and that makes it a less natural fit for large analytical scans and aggregations.
[1] quoted from https://www.postgresql.org/
At the same time, the lakehouse approach is steadily becoming the default for analytics: Separation of storage and compute architecture, based on open columnar file format (often Parquet). Table Formats like Delta Lake and Apache Iceberg brought this model mainstream, but they suffer from complexity in metadata management. DuckLake is the new participant that keeps SQL catalog metadata while storing open Parquet data files.
pg_ducklake sits right at the intersection of these worlds: it brings a native lakehouse experience into PostgreSQL, while keeping accessbility from DuckDB ecosystem
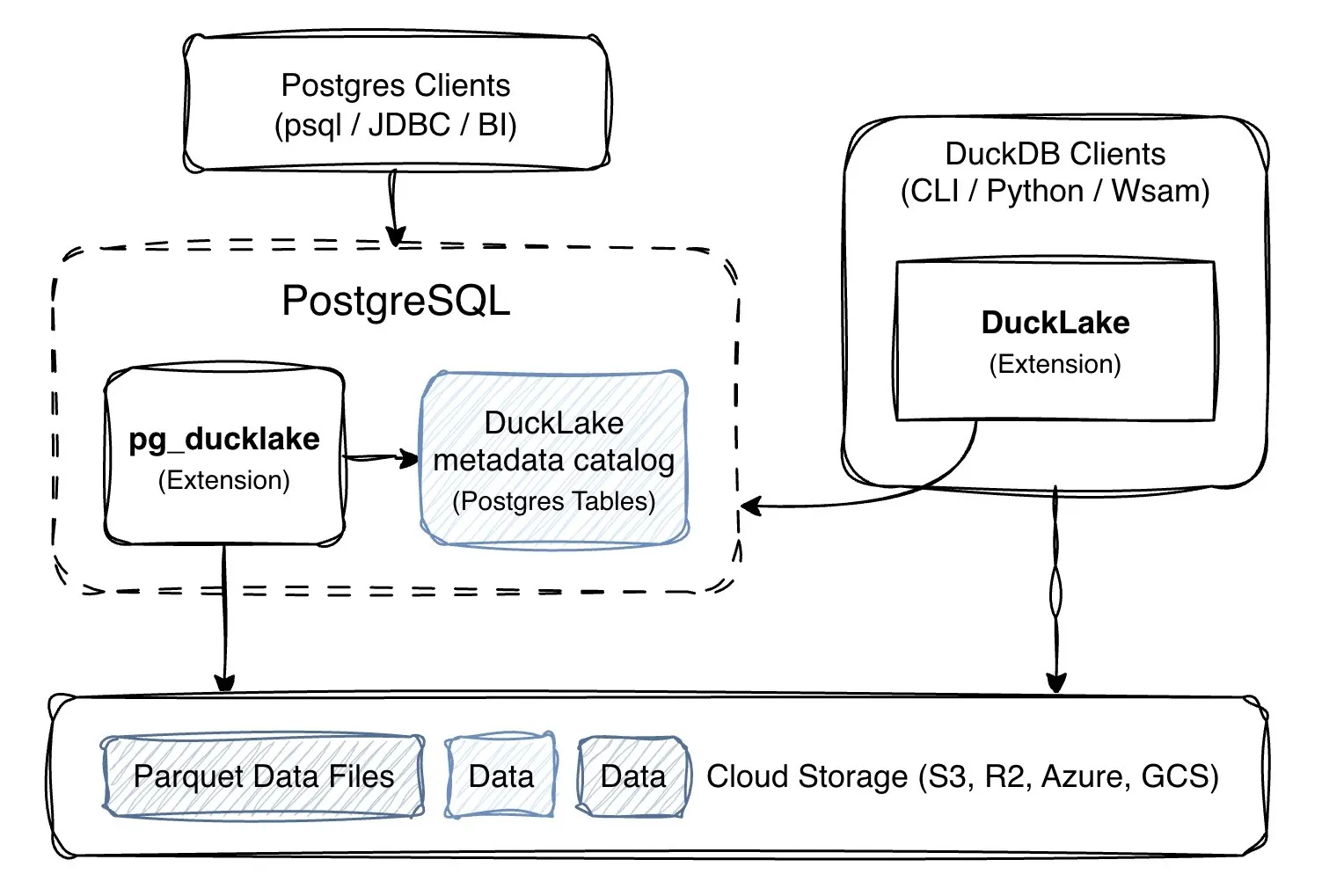
PostgreSQL × DuckDB × DuckLake
pg_ducklake creates a unified experience by bridging these three components:
- PostgreSQL provides the Interface and Catalog: You manage and query tables using familiar Postgres SQL, while all table metadata is stored natively in PostgreSQL heap tables.
- DuckDB powers the Execution Engine: A vectorized DuckDB engine is embedded directly within the PostgreSQL backend to handle analytical scans and aggregations with high efficiency.
- DuckLake serves as the Storage Format: It defines the “open” nature of the data—combining Parquet files on S3 with the metadata in Postgres—ensuring that external DuckDB clients (CLI, Python, etc.) can also access the same tables.
What pg_ducklake brings
The goal is simple: use PostgreSQL normally, but get lakehouse-style tables when you need them.
- Postgres-native ergonomics: DuckLake tables are managed from PostgreSQL, using familiar SQL and tooling — so they fit naturally into Postgres apps, BI and analyst workflows. In replica-friendly deployments (e.g., serverless Postgres setups like Neon), you can often scale read-heavy analytics by adding read replicas.
- Open tables by default: Parquet data + Postgres catalog; DuckDB clients (e.g., CLI, Python) can read the “raw” ducklake table by using Postgres as the metadata provider.
- DuckDB speed for analytics: vectorized execution + columnar storage for scans and aggregations.
What’s next for pg_ducklake
pg_ducklake is under active development, and we’re aiming toward a production-grade lakehouse experience inside PostgreSQL. On the roadmap are practical features like schema evolution, time travel, partitioning / layout controls, and table maintenance (compaction / garbage collection) — along with clearer operational guidance as more real-world users kick the tires.
Feedback and contributions are very welcome — especially real-world workloads, feature requests, and sharp edges you run into.
pg_ducklake: Native lakehouse tables in PostgreSQL—Open data, DuckDB speed.