@qianzhen
Jan 23, 2026
pg_ducklake has achieved a top-10 ranking in the ClickBench benchmark. If you’re a PostgreSQL user looking for better analytical query performance, you can now get ClickBench-class results without leaving your existing tech stack. No migration, no new infrastructure, just an extension.
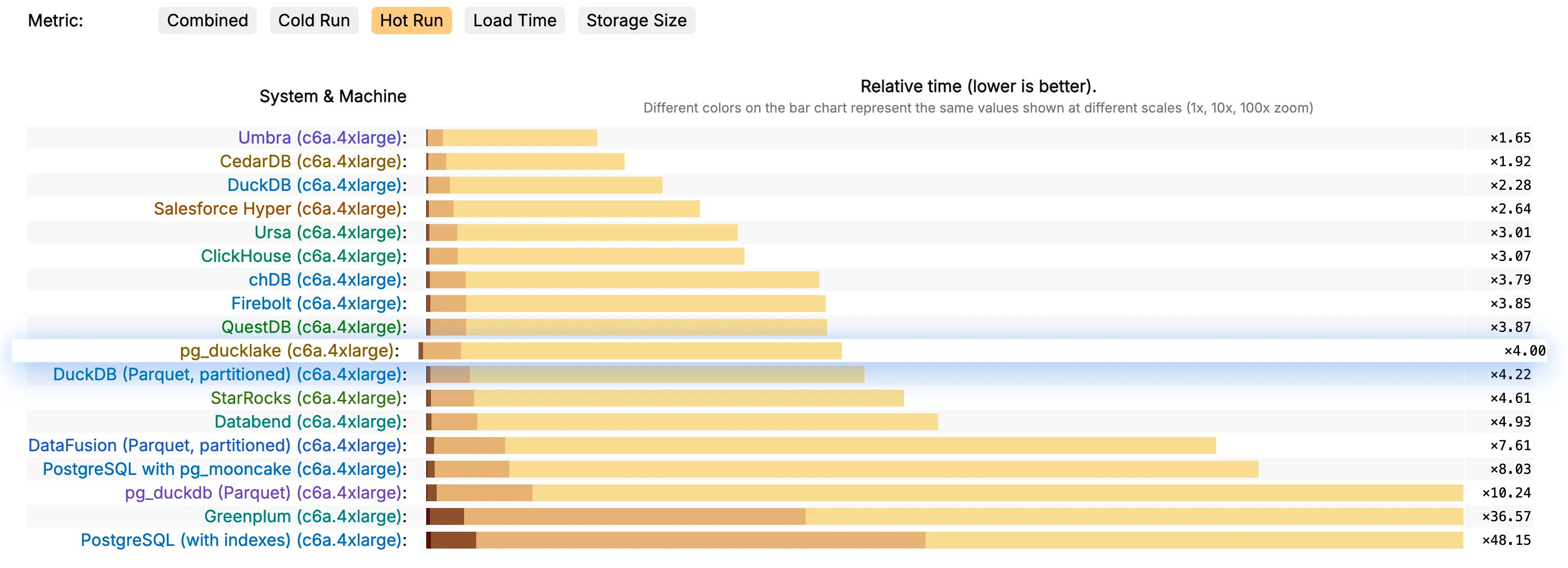
About the benchmark: ClickBench is an independent benchmark measuring real-world analytical query performance across different systems—from traditional databases to specialized OLAP engines.
Under the Hood
Here’s the complete picture of how a query flows through pg_ducklake:
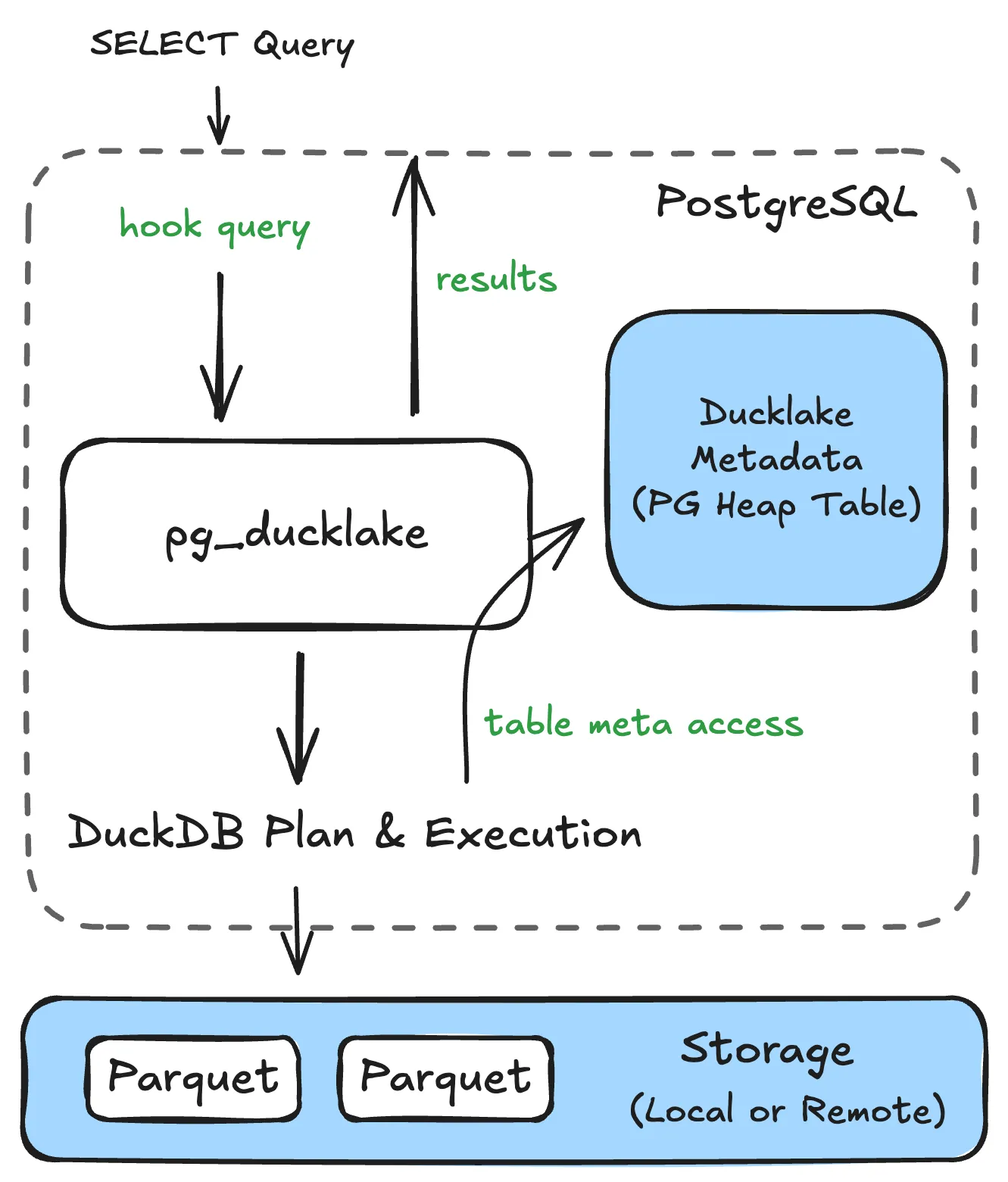
- A SELECT query arrives at PostgreSQL.
- pg_ducklake hooks the query if any DuckLake table is accessed, and hands the query to DuckDB.
- DuckDB plans the query, access DuckLake metadata (a group of Postgres heap tables), reads necessary Parquet files, and performs the query on them.
- Results flow back through pg_ducklake, are converted to PostgreSQL tuples, and returned to the client.
The three pillars of performance:
- Vectorized execution does the heavy lifting: optimized operators, SIMD instructions, and efficient memory usage deliver the raw query speed.
- Columnar storage format enables column pruning, compression, and minimal data scanning storage.
- Postgres-backed metadata eliminates catalog service overhead by accessing metadata in-memory, directly from Postgres heap tables. Unlike Apache Iceberg or Delta Lake that require network round-trips to remote catalog services, pg_ducklake delivers instant metadata access for file pruning and query planning.
Why pg_ducklake outperforms DuckDB on Parquet
In the ClickBench results above, pg_ducklake outperforms DuckDB on raw Parquet files. The reason lies in metadata management (in-memory metadata access). It enables file pruning and inter-file filtering (row-group level) without touching data files at all.
Consider an example: Given a partitioned table with hundreds of Parquet files spread across time ranges, and run a query for data from the last 7 days:
SELECT user_id, SUM(revenue)
FROM events
WHERE event_date >= CURRENT_DATE - INTERVAL '7 days'
GROUP BY user_id;With DuckDB reading raw Parquet files, the engine must list all files, read and parse each Parquet footer to identify which files to prune, and finally read the actual data. With pg_ducklake, all metadata operations, including min/max statistics and file boundaries, happen through in-memory Postgres heap table access, which is typically orders of magnitude faster than file-based metadata operations.
This is why pg_ducklake can deliver superior performance even compared to DuckDB’s already-fast Parquet scanning: the metadata layer makes intelligent file pruning essentially free.
The Vision: Open, Flexible, Fast
pg_ducklake brings a native lakehouse experience to PostgreSQL. Beyond performance and convenience, openness unlocks even greater value.
Query from PostgreSQL. pg_ducklake works seamlessly with the Postgres tech stack — scale analytics by spinning up read-only replicas, or leverage serverless architectures like Neon for elastic compute.
Access directly from DuckDB clients. Python scripts. Jupyter notebooks. Web apps. Your data science tools can read the same tables. No complex and expansive infrastructure. Just direct access.
Share data. Based on frozen DuckLake, you can export and import metadata between Postgres instances while data stays on object storage. This enables multiple teams to query independently with zero data duplication.
Get Involved
pg_ducklake is under active development, and we’re eager to hear from the community.
Try pg_ducklake today and share your feedback with us. Whether you’re running analytical workloads, building data pipelines, or exploring modern data architectures, we’d love to learn how pg_ducklake fits into your workflow — and how we can make it even better.